In 2018, as I embarked on my journey to develop machine vision models, I found myself working with a unique dataset – segmented images of kangaroos. My goal was to create a model capable of detecting and subsequently counting the number of kangaroos in a given region. The images I used were snapshots of the Australian outback, captured while I was precariously hanging out of a helicopter.
After spending several days separating the kangaroos from the background in these images, I was ready to test a variety of new Deep Neural Network (DNN) architectures. My aim was to identify the most effective model for my specific needs. I set my TensorFlow pipeline in motion to train six different base models from scratch, along with a few variations of each.
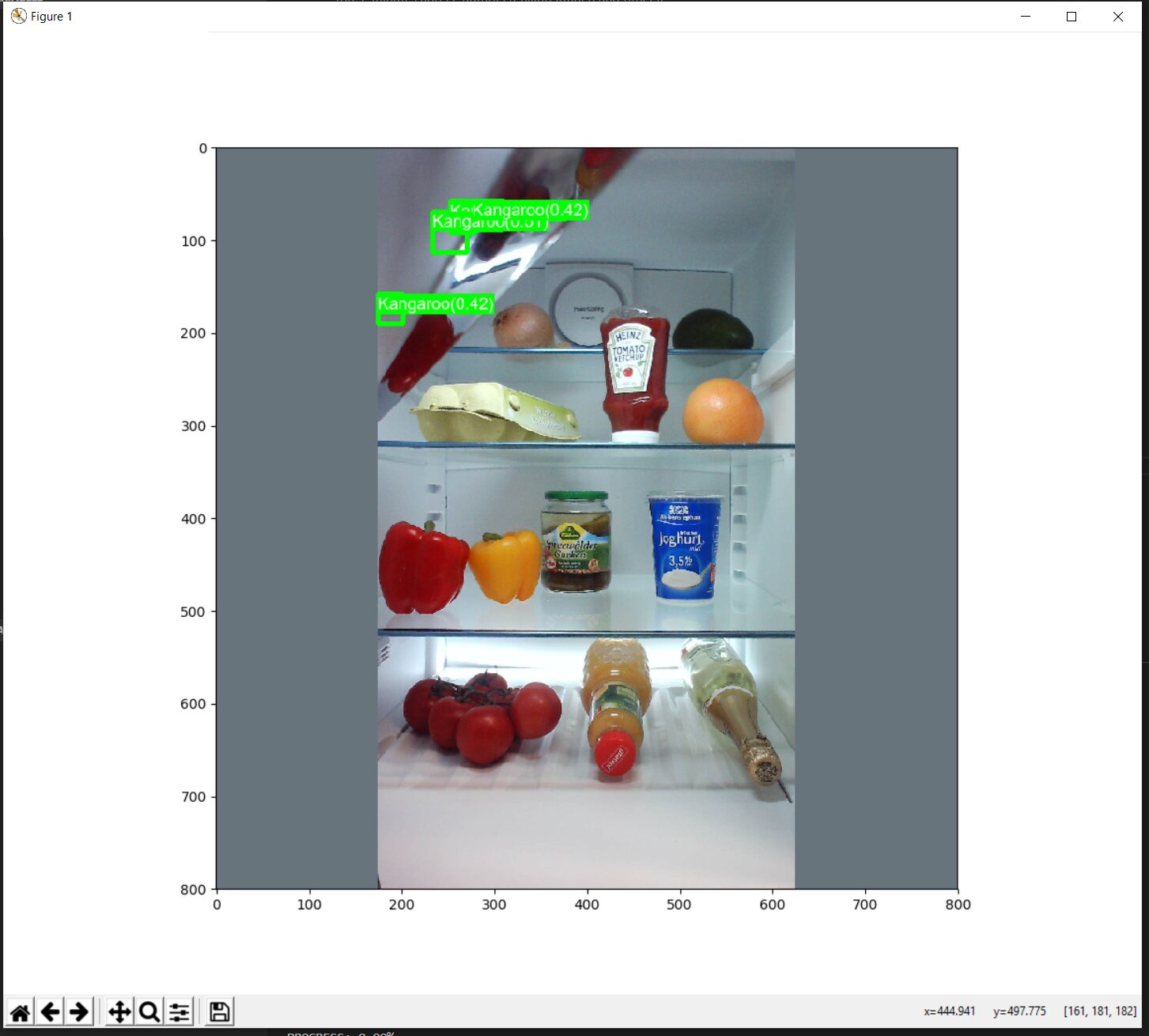
However, during the validation cycle, I made a significant error. Instead of using the set of images that had been set aside for validation, I inadvertently used a directory filled with photos of the interiors of fridges from the CNTK dataset1. This mistake turned out to be a pivotal learning moment in understanding how DNNs operate when inferring images outside of their training domain.
As a human, I can look at an image and immediately understand that it’s highly unlikely to find kangaroos in my fridge. However, the model lacked this contextual understanding and produced a result indicating a low “confidence” of kangaroo presence in the fridge. This incident sparked the development of several concepts that I later incorporated into our Machine Learning and DNN training systems. These concepts included:
- Torture Dataset: A collection of unusual images that were either adjacent to or outside the domain.
- Custom Metrics: Measures to evaluate the model’s performance on out-of-domain images.
- Domain-specific Language and Jargon: Terminology that facilitated communication about what was considered “in domain” and “out of domain”.
- Model Output “Escapes”: Essentially, the “I don’t know” option for the model.
- Data Provenance or Lineage: Understanding the origin of data and how it related to training and evaluation loops.
This experience continues to serve as a reminder that even in the realm of machine learning, the algorithm is missing key context, and not as “smart” as it would seem.